What is Apache HCatalog?
A developer-friendly introduction to Apache HCatalog, its architecture, features, and how it fits into the Hadoop ecosystem. —
Table of Contents
Introduction
Managing data storage and metadata in Hadoop can be complex, especially when using multiple processing tools like Hive, Pig, and MapReduce. Apache HCatalog simplifies this by providing a table abstraction and metadata services, making it easier to read and write data across the Hadoop ecosystem.
What is HCatalog?
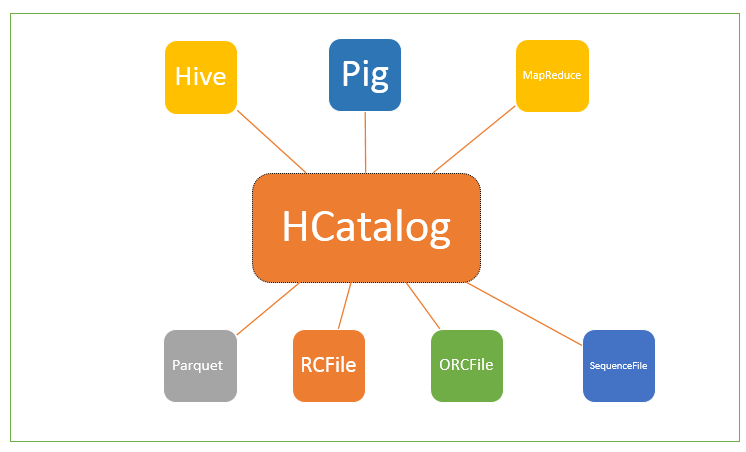
Apache HCatalog is a table and storage management layer for Hadoop. It enables users of different data processing tools (Hive, Pig, MapReduce) to easily read and write data from the cluster, regardless of how or where the data is stored.
- Provides a relational view of data stored in HDFS (e.g., RCFile, Parquet, ORC, SequenceFile, CSV, JSON)
- Exposes a REST API for external systems to access metadata
- Built on top of the Hive Metastore
Key Features
- Table Abstraction: Users don’t need to know the physical location or format of data
- Data Availability Notifications: Tools can be notified when new data is available
- Metadata Visibility: Data cleaning and archiving tools can access metadata
- REST API: External tools can access metadata and table definitions
How HCatalog Works
- HCatalog uses the Hive Metastore to store metadata about tables, partitions, and schemas
- Supports reading and writing files in any format for which a Hive SerDe (serializer-deserializer) exists
- By default, supports RCFile, Parquet, ORC, CSV, JSON, and SequenceFile formats
- For custom formats, provide the InputFormat, OutputFormat, and SerDe
- Presents a relational view: data is stored in tables, which can be partitioned and grouped into databases
- Provides read/write interfaces for Pig and MapReduce, and uses Hive CLI for DDL and metadata exploration
- REST interface allows external tools to perform DDL operations (e.g., create table, describe table)
Supported File Formats
- RCFile
- Parquet
- ORCFile
- CSV
- JSON
- SequenceFile
- Custom formats (with user-provided SerDe and Input/OutputFormat)
HCatalog Architecture
- Hive Metastore: Central metadata repository
- HCatalog Server: Provides REST API and interfaces for Pig, MapReduce, and external tools
- SerDe: Serializer/Deserializer for various file formats
- Table Abstraction: Logical view over physical data
Integration with Other Tools
- Hive: HCatalog is built on top of Hive Metastore and uses Hive DDL for table management
- Pig: Pig scripts can read/write HCatalog tables without worrying about file formats
- MapReduce: MapReduce jobs can use HCatalog InputFormat/OutputFormat to access tables
- External Tools: Can use the REST API for metadata operations
For an example of HCatalog integration with Pig, see this guide.