Why Apache Iceberg is the Game-Changer Your Data Lake Needs
Still relying on traditional data lakes with unreliable reads, lack of ACID guarantees, and painful schema evolution?
Welcome to Apache Iceberg—an open table format purpose-built for modern, petabyte-scale analytics. With native support for engines like Apache Spark, Trino, Presto, Hive, and Flink, Iceberg solves the biggest challenges in big data processing.
In this post, we’ll break down:
- What Apache Iceberg is and why it matters
- How its architecture works (with a visual!)
- Key features that make it future-ready
- Real-world use cases
- A call to action for your next data platform decision
What Is Apache Iceberg?
Apache Iceberg is an open table format designed for large-scale, high-performance analytic datasets. Think of it as a replacement for Hive tables—but with versioning, schema evolution, partition evolution, hidden metadata management, and more.
Iceberg tables abstract the storage layer, providing a transactional and query-optimized interface to object stores like Amazon S3, Google Cloud Storage, or HDFS.
The Problem Iceberg Solves
Modern data lakes often suffer from:
- Data corruption due to concurrent writes
- Inefficient metadata scanning as datasets scale
- No schema or partition evolution
- Inconsistent read/write behavior
Apache Iceberg fixes all of these by introducing:
- Atomic transactions
- Snapshot isolation
- Efficient metadata tracking
- Time travel and rollback capabilities
Apache Iceberg Architecture: How It Works
Below is a visual representation of Iceberg’s architecture:
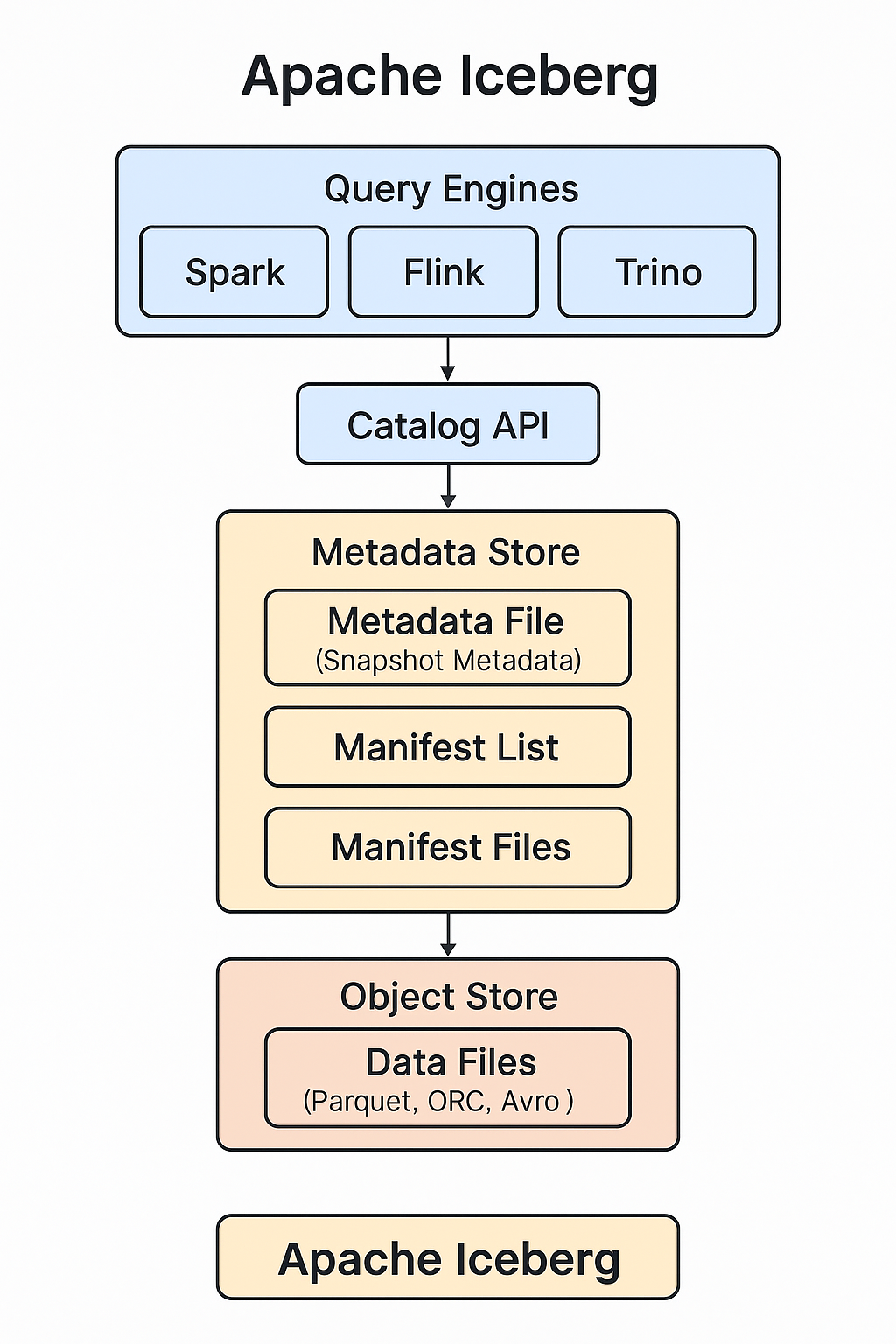
Key Components:
-
Data Files
Actual columnar data in formats like Parquet, ORC, or Avro stored in object storage. -
Manifest Files
Lists data files and partition information. Each snapshot has associated manifests. -
Manifest Lists
Pointers to manifest files—each snapshot has a manifest list. -
Metadata File (Snapshot Metadata)
Tracks the current snapshot, schema, partition spec, table properties. -
Snapshot Management
Supports time travel, rollback, and branching via snapshot history. -
Query Engines
Spark, Flink, Trino, and others communicate with Iceberg through catalog APIs to read consistent snapshots.
This separation of metadata and data, along with efficient query planning, is what makes Iceberg highly scalable.
Top Features That Make Iceberg Stand Out
✅ ACID Compliance at Scale
Iceberg guarantees atomicity, consistency, isolation, and durability—even on distributed object stores.
🔁 Time Travel & Rollbacks
Go back to any previous snapshot to debug or audit data.
📐 Schema Evolution
Add, rename, or delete columns without breaking queries.
📦 Partition Evolution
Change partitioning strategy midstream—no need to rewrite existing data.
🚀 Engine Agnostic
Query from Spark, Trino, Flink, Hive, and even Snowflake (beta support).
📊 Hidden Partitioning
No need to specify partitions in queries—Iceberg handles it via metadata.
Apache Iceberg vs Delta Lake vs Hudi
| Feature | Apache Iceberg | Delta Lake | Apache Hudi |
|---|---|---|---|
| ACID Transactions | ✅ | ✅ | ✅ |
| Time Travel | ✅ | ✅ | ✅ |
| Schema Evolution | ✅ | ✅ | Limited |
| Partition Evolution | ✅ | ❌ | ❌ |
| Multi-Engine Support | ✅ | Limited (mostly Spark) | Limited |
| Cloud Native | ✅ | ✅ | ✅ |
Iceberg is increasingly being adopted by companies looking for a vendor-neutral, truly open format that scales well and integrates cleanly with multiple compute engines.
Use Cases for Apache Iceberg
🏦 Financial Services
Track every transaction with auditability and rollback support.
📺 Streaming Platforms
Ingest terabytes of data in real time using Flink or Kafka, and query it instantly using Trino.
🛒 E-Commerce Analytics
Combine batch and real-time data pipelines with schema changes that evolve with business.
🌍 Global Data Platforms
Multi-cloud or hybrid-cloud strategies work seamlessly due to engine and cloud agnosticism.
Getting Started with Apache Iceberg
Tools You Can Use
- Apache Spark + Iceberg Connector
- Trino with Iceberg catalog plugin
- AWS Glue, EMR with Iceberg support
- Iceberg REST Catalog or Nessie for versioned catalogs
Example: Creating an Iceberg Table in Spark
spark.sql("""
CREATE TABLE customers (
id BIGINT,
name STRING,
email STRING
) USING iceberg
PARTITIONED BY (bucket(16, id))
""")
Future-Proof Your Data Lake with Iceberg Today
If you’re building or re-architecting your data platform, don’t settle for outdated table formats.
Apache Iceberg is the open, scalable, and reliable foundation your modern data stack needs.
👉 Try it out with Spark or Trino today. 👉 Join the Apache Iceberg community on GitHub. 👉 Check out vendors like Dremio, Tabular, or Snowflake for managed solutions.