With the rise of cloud-native data architectures and serverless computing, data engineers face a crucial decision when designing big data pipelines: HDFS or Object Storage? This decision impacts performance, scalability, fault tolerance, and cost. In this post, we’ll conduct a deep technical analysis of both storage systems and explore how they align with modern big data processing patterns on the cloud.
📘 HDFS: A Distributed Filesystem Born for Hadoop
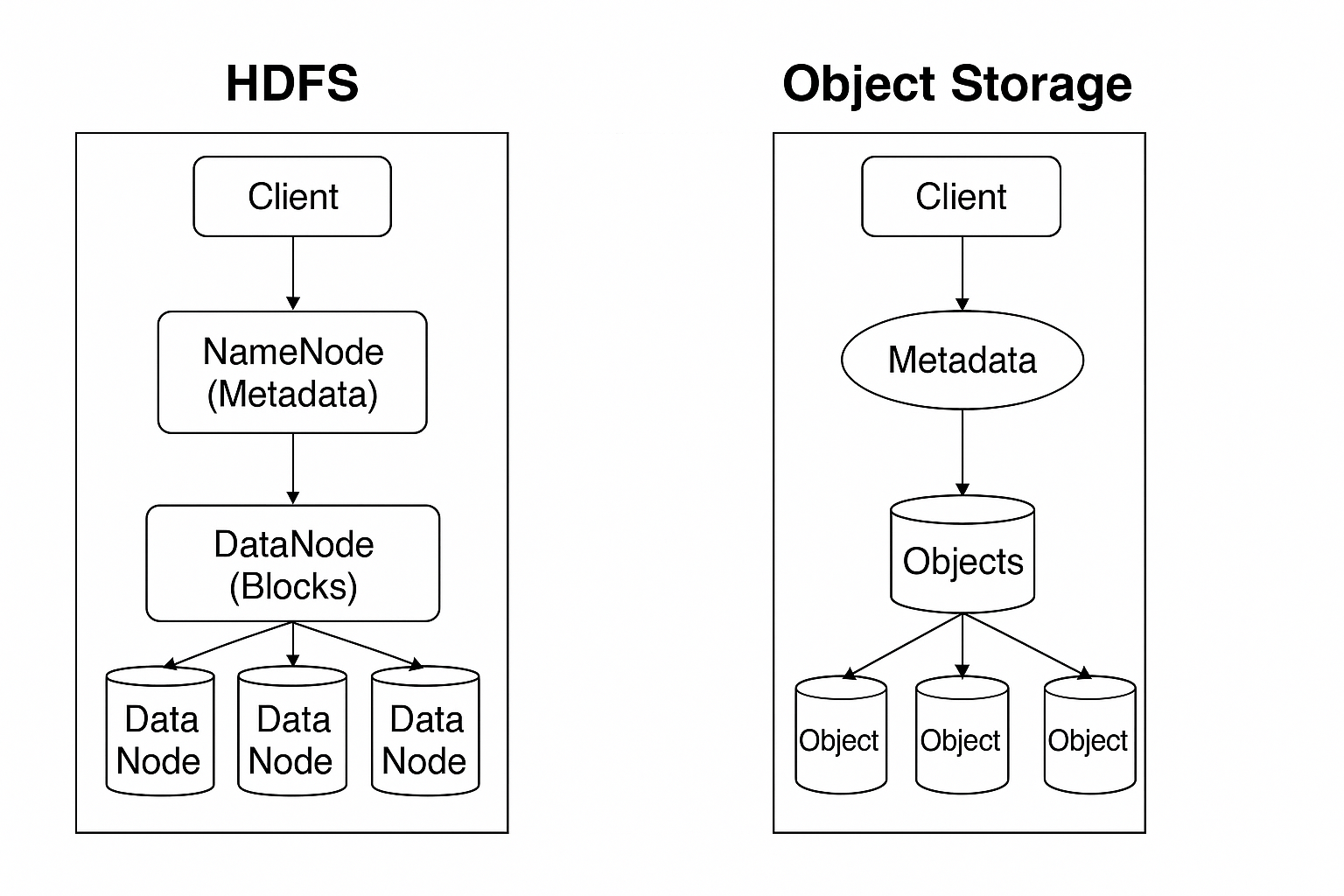
HDFS is a high-throughput, distributed file system optimized for large-scale batch processing. It is tightly integrated with the Hadoop ecosystem, designed to run on commodity hardware with locality-aware scheduling.
HDFS Architecture:
- NameNode: Centralized metadata service. Tracks file hierarchy, block locations, replication.
- DataNodes: Store actual data blocks (typically 128 MB or 256 MB).
- Client: Reads metadata from NameNode and streams data directly from DataNodes.
Characteristics:
- POSIX-like interface: Supports directories, permissions, and hierarchical structure.
- Strong consistency: Write-once, read-many semantics.
- Default replication factor: 3, with rack-awareness for fault tolerance.
- Low-latency access within the cluster.
- No support for random writes or in-place updates.
☁️ Object Storage: Cloud-native and Massively Scalable
Object Storage (Amazon S3, Google Cloud Storage, Azure Blob) decouples storage from compute. It stores data as immutable objects, each with a globally unique identifier and rich metadata.
Object Storage Architecture:
- Flat namespace: Hierarchical paths are logical (e.g.,
s3://bucket/folder/file) but not native. - Objects: Consist of a byte stream, metadata, and unique key.
- Durability: 99.999999999% (11 nines), often via erasure coding.
- Versioning: Objects are immutable; updates create new versions.
Characteristics:
- Eventual consistency (strong consistency now available in S3).
- Access via RESTful API (e.g.,
GET,PUT,DELETE). - Tiered storage (Standard, IA, Glacier).
- Scales to exabytes with no ops burden.
- Built-in encryption (SSE, KMS) and IAM-based access control.
🔍 Deep Comparison: HDFS vs Object Storage
1. Data Model and Metadata Handling
| Aspect | HDFS | Object Storage |
|---|---|---|
| Namespace | Hierarchical (POSIX-like) | Flat (bucket + object key) |
| Metadata | In-memory, centralized (NameNode) | Distributed, managed by cloud provider |
| Operations | open(), read(), seek(), mkdir() |
REST: GET, PUT, HEAD, no seek() |
| Limitations | NameNode memory limits scalability | No hard limits on objects or namespaces |
In HDFS, all file/block metadata is stored in the NameNode’s heap, making it a scalability bottleneck. In contrast, object storage abstracts this behind a scalable metadata service.
2. Consistency and Semantics
- HDFS: Strong consistency — once a write is acknowledged, it is guaranteed to be durable and visible to all readers.
- S3/GCS/Azure: Previously eventually consistent (S3 now strongly consistent for new puts/deletes), but some API semantics differ — e.g., no atomic renames.
Implications:
- Many big data tools rely on rename-based commit protocols (e.g., Spark’s
_temporarydirectory logic). - Object storage requires compatibility layers (
FileOutputCommitter,S3Guard, Delta Lake, Iceberg) to ensure atomicity.
3. Performance
| Workload Type | HDFS (on HDFS-aware cluster) | Object Storage (e.g., S3) |
|---|---|---|
| Write Latency | Low (local disks, pipeline write) | Higher (network + eventual fs ops) |
| Read Throughput | High (data locality) | High parallelism, lower locality |
| Metadata Ops | Fast (NameNode) | Slow (LIST, HEAD, object listings) |
| Optimizations | Write coalescing, compression | Parallel reads, multipart uploads |
In Spark, reading from HDFS benefits from data locality and fast shuffle spill. On object storage, throughput scales with the number of threads and proper tuning (e.g., spark.hadoop.fs.s3a.connection.maximum).
4. Scalability and Fault Tolerance
- HDFS:
- Limited by NameNode memory (~1 GB heap = ~1 million blocks).
- Manual rebalancing and replication management.
- Suitable for clusters with 10s-100s of nodes.
- Object Storage:
- Virtually infinite scaling.
- Built-in geo-replication, erasure coding, automatic failover.
- Ideal for multi-region and global data lake architectures.
5. Cost Comparison
| Factor | HDFS (self-managed) | Object Storage (cloud-native) |
|---|---|---|
| Storage Cost | Pay for attached disks/VMs | Pay per GB per month |
| Access Cost | Free (within cluster) | Request + egress + retrieval charges |
| Ops & Maintenance | High (monitoring, balancing) | Low (fully managed) |
| Cold/Archive Tiering | Manual | Built-in (e.g., Glacier, Nearline) |
Pro tip: For cost-sensitive workflows, pair object storage with query engines like Presto, Athena, or BigQuery to avoid full pipeline execution.
6. Integration with Big Data Tools
- Apache Spark:
- HDFS: Uses
FileSystemAPIs directly. - Object Storage: Uses
s3a://,gs://,wasb://, with optimizations likeFastOutputCommitter, Parquet pushdown, partition pruning.
- HDFS: Uses
- Hive/Trino:
- Compatible with both, but large metadata overhead on object storage if not using columnar formats or partitioned tables.
- Flink:
- Uses
CheckpointStorageabstractions that work with S3 and HDFS. - Checkpointing in object storage requires tuning for latency.
- Uses
- Delta Lake/Iceberg/Hudi:
- Enable ACID on object stores.
- Write-friendly formats that abstract out rename issues and provide snapshot isolation.
7. Security, Auditing, and Compliance
| Feature | HDFS | Object Storage (e.g., S3) |
|---|---|---|
| Authentication | Kerberos | IAM, OAuth, STS |
| Authorization | POSIX ACLs | Bucket policies, ACLs, condition keys |
| Encryption | HDFS Transparent Encryption | SSE-S3, SSE-KMS, client-side |
| Audit Logs | Manual (Audit logs via NameNode) | Native (CloudTrail, GCP Audit Logs, etc.) |
Object storage wins in cloud compliance due to out-of-the-box logging, encryption, and integration with security frameworks.
🧪 Use Cases: What to Choose When?
| Scenario | Preferred Storage |
|---|---|
| On-prem Hadoop cluster | HDFS |
| Cloud-native ETL/ELT pipelines | Object Storage |
| Long-term archival | Object Storage (cold tier) |
| Realtime ML pipelines | HDFS (low-latency staging) |
| Lakehouse architecture | Object Storage + Delta/Iceberg |
🔁 Hybrid Patterns and Migration
Many enterprises adopt hybrid patterns:
- Ingestion → Staging (HDFS) → Persistent Store (S3)
- Delta Lake on S3 with Spark jobs in EKS/EMR
- Use DistCp or Apache NiFi to move data from HDFS to S3
Best Practices:
- Use open formats like Parquet or ORC.
- Avoid small files: use
coalesce()and file compaction. - Use object store-aware committers and concurrency-safe tools.
✅ Conclusion
HDFS laid the foundation for scalable big data systems, but the demands of elasticity, operational simplicity, and cloud-native scale have made object storage the modern default.
In 2025 and beyond, big data is no longer coupled to HDFS. If you’re building a cloud-first, lakehouse-style data platform, object storage is where you begin — with HDFS playing a transitional or niche role.
💬 Let’s Discuss
Have you migrated from HDFS to Object Storage? Are you dealing with atomic rename issues or tuning Spark for S3? Share your experiences or questions in the comments section!