HiveServer2 (HS2) is a server interface that enables remote clients to execute queries against Hive and retrieve the results. The current implementation, based on Thrift RPC, is an improved version of HiveServer and supports multi-client concurrency and authentication. It is designed to provide better support for open API clients like JDBC and ODBC.

In this post, we will see how we can start HiveServer2 and connect to it with a JDBC Client:
Part 1 : How to Start HiveServer2 (Hive as a service)
$HIVE_HOME/bin/hiveserver2
OR
$HIVE_HOME/bin/hive --service hiveserver2
You should see something like this on console:
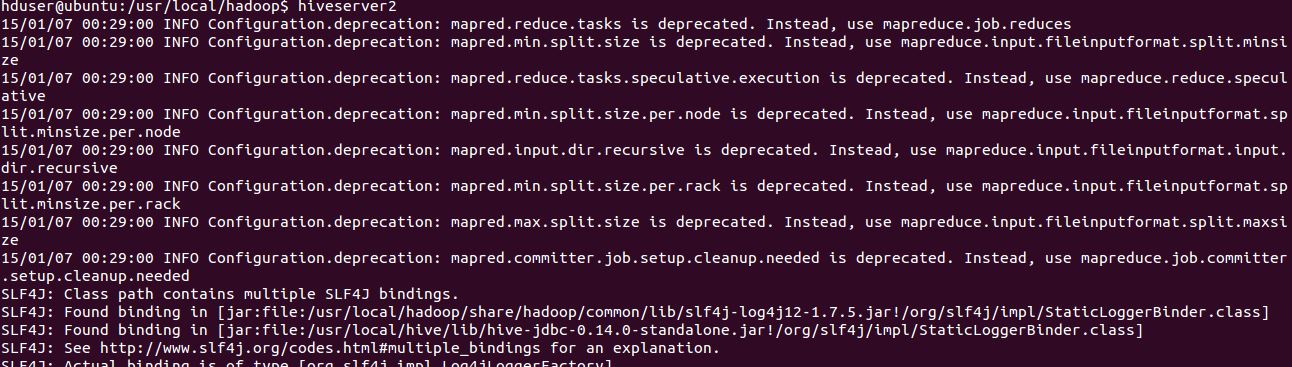
A quick way to check if HiveServer2 is running is to use the netstat command to see if port 10000 is open and listening to connections:
$ netstat -nl | grep 10000
Now we are all set to connect to the above started Hive Service and we can connect our JDBC client to the server to create tables, write queries over it, etc.
Part 2 : Using JDBC to Connect to HiveServer2
You can use JDBC to access data stored in a relational database or other tabular format.
-
Load the HiveServer2 JDBC driver.
For example:
Class.forName("org.apache.hive.jdbc.HiveDriver"); -
Connect to the database by creating a
Connectionobject with the JDBC driver.For example:
Connection cnct = DriverManager.getConnection("jdbc:hive2://<host>:<port>", "<user>", "<password>");The default
<port>is 10000. In non-secure configurations, specify a<user>for the query to run as. The<password>field value is ignored in non-secure mode.Connection cnct = DriverManager.getConnection("jdbc:hive2://<host>:<port>", "<user>", "");In Kerberos secure mode, the user information is based on the Kerberos credentials.
-
Submit SQL to the database by creating a
Statementobject and using itsexecuteQuery()method.For example:
Statement stmt = cnct.createStatement(); ResultSet rset = stmt.executeQuery("SELECT foo FROM bar"); -
Process the result set, if necessary.
Let’s understand this with an example:
We’ll create a text file with test values and read data with Hive and display using queries:
echo -e '1\x01foo' > /tmp/a.txt
echo -e '2\x01bar' >> /tmp/a.txt
Test Java Client
We need to add the following Maven dependencies:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>0.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>0.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>0.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service</artifactId>
<version>0.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-avatica</artifactId>
<version>0.9.2-incubating</version>
</dependency>
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>0.9.2-incubating</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.2.0</version>
</dependency>
And let’s create one Test Java Program:
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveJdbcClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
/**
* @param args
* @throws SQLException
*/
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.exit(1);
}
//replace "hduser" here with the name of the user the queries should run as
Connection con = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "hduser", "");
Statement stmt = con.createStatement();
String tableName = "testHiveDriverTable";
stmt.execute("drop table if exists " + tableName);
stmt.execute("create table " + tableName + " (key int, value string)");
// show tables
String sql = "show tables '" + tableName + "'";
System.out.println("Running: " + sql);
ResultSet res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
// describe table
sql = "describe " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
// load data into table
// NOTE: filepath has to be local to the hive server
// NOTE: /tmp/a.txt is a ctrl-A separated file with two fields per line
String filepath = "/tmp/a.txt";
sql = "load data local inpath '" + filepath + "' into table " + tableName;
System.out.println("Running: " + sql);
stmt.execute(sql);
// select * query
sql = "select * from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
}
// regular hive query
sql = "select count(1) from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
}
}
When we run the Test JDBC Client, output on console looks like:
Running: show tables 'testHiveDriverTable'
testhivedrivertable
Running: describe testHiveDriverTable
key int
value string
Running: load data local inpath '/tmp/a.txt' into table testHiveDriverTable
Running: select * from testHiveDriverTable
1 foo
2 bar
Running: select count(1) from testHiveDriverTable
2
And on the HiveServer2 Screen you should see corresponding output and processing of MapReduce Jobs for each query, something like this:
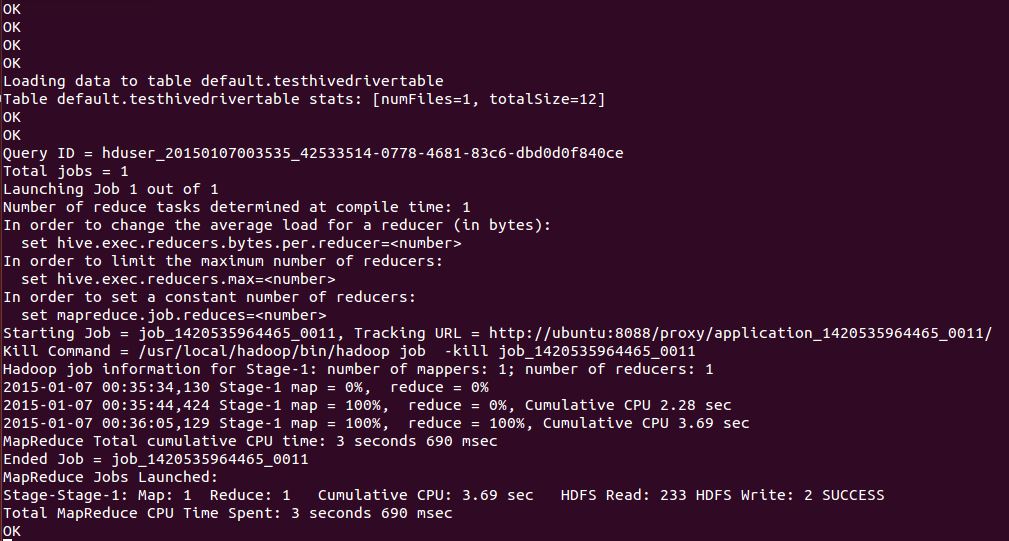
That’s it! We are all set with a HiveServer2 running and successfully connected with a JDBC Client.
Happy Learning!!