Once we know something, we find it hard to imagine what it was like not to know it.
— Chip & Dan Heath, Authors of Made to Stick, Switch
What is the ELK stack?
The ELK stack consists of open source tools ElasticSearch, Logstash, and Kibana. These three provide a fully working real-time data analytics tool for getting wonderful information sitting on your data. ElasticSearch
ElasticSearch, built on top of Apache Lucene, is a search engine with focus on real-time analysis of the data, and is based on the RESTful architecture. It provides standard full text search functionality and powerful search based on query. ElasticSearch is document-oriented/based and you can store everything you want as JSON. This makes it powerful, simple and flexible.
Logstash
Logstash is a tool for managing events and logs. You can use it to collect logs, parse them, and store them for later use. In ELK Stack, Logstash plays an important role in shipping the log and indexing them later which can be supplied to ElasticSearch.
Kibana
Kibana is a user friendly way to view, search and visualize your log data, which will present the data stored from Logstash into ElasticSearch, in a very customizable interface with histogram and other panels which provides real-time analysis and search of data you have parsed into ElasticSearch.
How do I get it?
https://www.elastic.co/downloads
How do they work together?
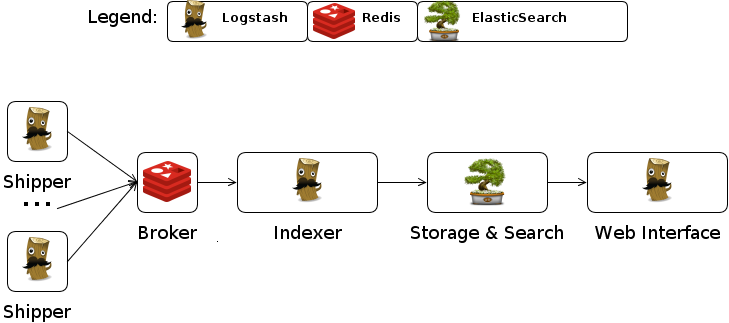
Logstash is essentially a pipelining tool. In a basic, centralized installation a logstash agent, known as the shipper, will read input from one to many input sources and output that text wrapped in a JSON message to a broker. Typically Redis, the broker, caches the messages until another logstash agent, known as the collector, picks them up, and sends them to another output. In the common example this output is Elasticsearch, where the messages will be indexed and stored for searching. The Elasticsearch store is accessed via the Kibana web application which allows you to visualize and search through the logs. The entire system is scalable. Many different shippers may be running on many different hosts, watching log files and shipping the messages off to a cluster of brokers. Then many collectors can be reading those messages and writing them to an Elasticsearch cluster.
How do I fetch useful information out of logs?
Fetching useful information from logs is one of the most important parts of this stack and is being done in Logstash using its grok filters and a set of input, filter, and output plugins which help to scale this functionality for taking various kinds of inputs (file, tcp, udp, gemfire, stdin, unix, web sockets and even IRC and twitter and many more), filter them using (groks, grep, date filters etc.) and finally write output to ElasticSearch, redis, email, HTTP, MongoDB, Gemfire, Jira, Google Cloud Storage etc.
A bit more about Logstash

Filters
Transforming the logs as they go through the pipeline is possible as well using filters. Either on the shipper or collector, whichever suits your needs better. As an example, an Apache HTTP log entry can have each element (request, response code, response size, etc) parsed out into individual fields so they can be searched on more seamlessly. Information can be dropped if it isn’t important. Sensitive data can be masked. Messages can be tagged. The list goes on.
e.g.
[gist https://gist.github.com/saurzcode/da3b31f0496b5feba8c9 /]
Above example takes input from an apache log file, applies a grok filter with %{COMBINEDAPACHELOG}, which will index apache logs information on fields and finally output to Standard Output Console.
Writing Grok Filters
Writing grok filters and fetching information is the only task that requires some serious efforts and if done properly will give you great insights into your data like Number of Transactions performed over time, Which type of products have most hits etc.
Below links will help you a lot in writing grok filters and test them with ease:
Grok Debugger
Grok Debugger is a wonderful tool for testing your grok patterns before using in your logstash filters.
http://grokdebug.herokuapp.com/
Grok Patterns Lookup
You can lookup grok for various commonly used log patterns here:
https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
If you like this post you will love to read my book on ELK stack: https://www.packtpub.com/big-data-and-business-intelligence/learning-elk-stack. The book covers all the basics of Elasticsearch, Logstash and Kibana4 to get you started on ELK stack. Please find more details of the book here.
References
- http://www.elasticsearch.org/overview/
- http://logstash.net/
- http://rashidkpc.github.io/Kibana/about.html